A tricky query to optimize is partial match of phone numbers, this post will walk through some options.
We hit 100% DTU on user DB again yesterday, so we need to come up with a new solution for search ... We are considering both short term fixes ... But also more future-proof long term solutions like Elasticsearch, Azure Cognitive Search...
As is often common, at MAJORITY the slowest query is a generic search function in the admin tool that allows support agents to search for users. The above quote is from a recent spike in DTU usage were the engineer investigating identified this search function as the issue.
I have to admit, I'm a sucker for DB performance... And as shown by my post on Redis, I'm a fan of boring tech and using what you already have in your stack. So here's a deep dive into a pure SQL solution!
As always, the first thing to do is to look at the data, and, somewhat surprising this generic search function consists of 99% searches for mobile phone numbers. From now on I will refer to these as MSISDN as that is what we have and how we call them internally. That means the phone number is normalized to digits only including leading country code. Often these searches are partial, e.g. a support agent could search for 574400250 which would match the full 15744002507. To not write a whole book about text searching, lets focus on the specific case of partial matching of MSISDN only.
When searching for MSISDN the search query (~100 lines of T-SQL in a stored procedure) simplifies to a query like this:
select top 50 *
from [Users]
where Msisdn like '%ddd%'
order by Created desc;
where the ddd part is a variable number of digits entered by the
user performing the search. This is a notoriously tricky query to optimize in
most SQL databases since you cannot just add a common B-Tree index to fully
solve it. See for example the classic guide on indexing,
Use The Index, Luke, which warns
Avoid LIKE expressions with leading wildcards (e.g., '%TERM').
.
Before we try any ideas on how to solve this within SQL Server, let's start by establishing a baseline in a local DB to have something to benchmark against.
The table in question is something like this
create table U (
UserId uniqueidentifier primary key not null,
Created datetime not null,
Updated datetime not null,
Msisdn nvarchar(20) not null,
... 10 more columns
)
If you look carefully something already stand out as very non-optimal here, can you see what it is?
Anyway, regardless of obvious issues, lets focus and create a baseline first!
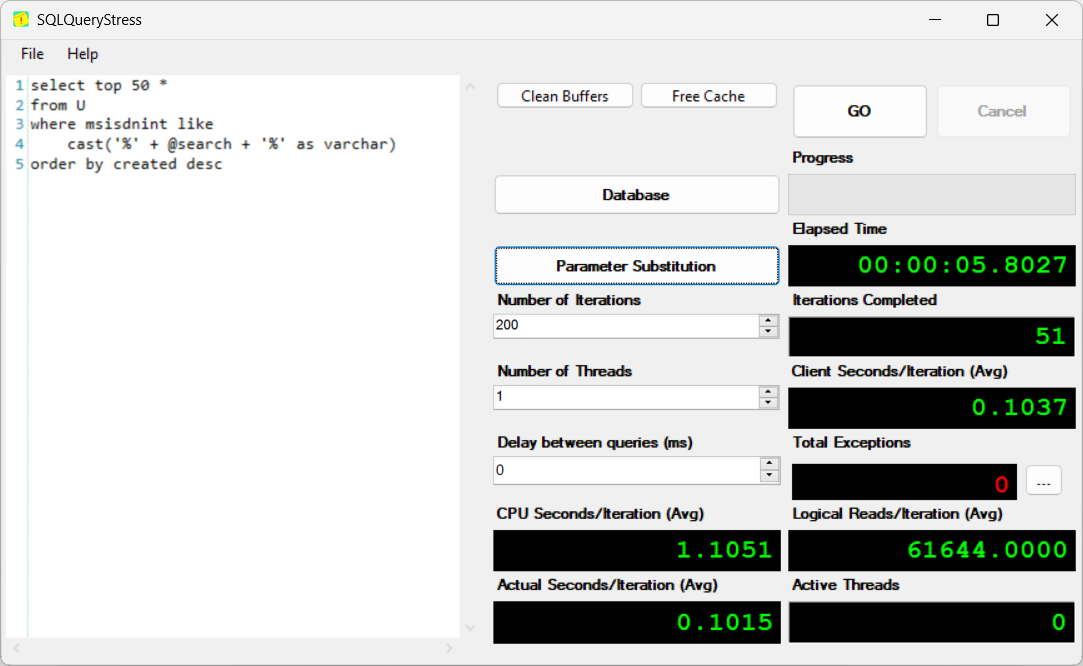
To benchmark, I copied over production like data (1.7m rows) into a local instance of SQL Server running on my laptop (a Surface Pro), and then ran the query above using SqlQueryStress. To make realistic load I used its parameter substitution function to select out some random MSISDNs, then cut a bit from the beginning/end and return:
select search from (
select top 200,
cast(substring(
Msisdn,
abs(checksum(UserId)) % 7,
4+abs(checksum(Created)) % 16
) as varchar(20)) as search
from U
order by checksum(UserId)
) x
where len(search)>3
Why such a complicated query you might wonder? I want to take rows in somewhat random order, and I want to cut the beginning and end randomly. In this case the exact randomness is not very important, so I use the CHECKSUM function. This way its random, but also stable between runs. This is what it looks like in SQLQueryStress' parameter setup:

And this is the main window of the program, with a sneak peek of one of the things we will try later
The first query we try is the baseline / naive version, which looks like this when its parameterized:
select top 50 *
from U
where Msisdn like'%' + @search + '%'
order by Created desc
And the result?
| Test | Total time | Avg CPU (s) | Avg Actual (s) | Logical Reads |
|---|---|---|---|---|
| Baseline | 01:05.47 | 3.7452 | 0.3224 | 61644 |
The test runs 200 iteration. Each query take in average ~300ms, but spends almost 10x that on CPU, and reads the full table (61644 which is roughly the page count). In total the test ran in around 1 minute. Given I run this on my laptop, which has other unrelated processes running, dynamic frequency scaling etc the exact numbers should not be used, but used as a rough estimate when comparing tests.
Alright, with the baseline out of the way we come to the fun part and can
finally try some optimizations! You might already have spotted this when I
showed the table definition - the column that stores the MSISDN numbers are
nvarchar(20)! But a normalized MSISDN phone number is actually
always just digits 0-9 maximum 15 digits. There is absolutely no need to use a
data type that supports full Unicode! If anything it increases the chance that
something bad sneaks in.
For the test, I just added a new column,
MsisdnVarchar varchar(20) and copied over the values from the old
nvarchar column. Since it only contains digits this is easy:
alter table U add MsisdnVarchar varchar(20) not null default('');
update U set MsisdnVarchar = Msisdn;
To do this change in production is a bit more involved, one way is to add a new column, copy over the data, rename the old column to something else, rename the new column to the old name and finally remove the old now unused column. Preferably not during peak load. You might want to rebuild it in the end to clean up any fragmentation as well.
With this column in place, let's rerun the test with the new column as shown
below. Note that SQLQueryStress will not respect the datatype but use
nvarchar
for the parameter, so the query needs to cast @search to
varchar. If @search would be a
nvarchar SQL Server would need to run a slow conversion, and we
would not get the result we want:
select top 50 *
from U
where MsisdnVarchar like
cast('%' + @search + '%' as varchar)
order by Created desc
And the result? Very nice:
| Test | Total time | Avg CPU (s) | Avg Actual (s) | Logical Reads |
|---|---|---|---|---|
| Baseline | 01:05.47 | 3.7452 | 0.3224 | 61644 |
| Varchar Column | 00:18.75 | 0.9894 | 0.0884 | 61644 |
Result: 3.6x faster
We can see that just like the baseline query it needs to visit all the pages (a full table scan), but it uses much less CPU since it's much cheaper to handle non-Unicode data which is smaller and doesn't have the complex collation rules. Honestly, wearing my professional architect hat this result is good enough. No need to optimize further given the 1-2 million rows and the usage pattern (on the order of 100s-1000s of searches per hour).
But, luckily I take off that hat when I'm at home and can follow the rabbit
deeper! If we got this good speedup from a varchar column,
couldn't we store the MSISDN in a numeric type and gain even more? A MSISDN is
as we saw above at most 15 digits. That fits well within a
bigint which can store
18 digits (or 19 depending on how you treat negative numbers). It has a downside, it can't keep track of leading 0s. But luckily for us
MSISDNs does not start with 0s, it will always start with a country code.
For testing, we can add a new column MsisdnInt bigint and copy
over the values:
alter table U add MsisdnInt bigint not null default(0);
update U set MsisdnInt = cast(Msisdn as bigint);
In an old production table, there might be some cases of uncleaned data, if so that will need to be cleaned up first.
With this column in place, let's rerun the test with the new column as shown below
select top 50 *
from U
where MsisdnInt like
cast('%' + @search + '%' as varchar)
order by Created desc
And the result? A bit disappointing:
| Test | Total time | Avg CPU (s) | Avg Actual (s) | Logical Reads |
|---|---|---|---|---|
| Baseline | 01:05.47 | 3.7452 | 0.3224 | 61644 |
| Varchar Column | 00:18.75 | 0.9894 | 0.0884 | 61644 |
| Bigint Column | 00:18.94 | 1.0060 | 0.0895 | 61644 |
Result: 3.6x faster
As I mentioned earlier, the testing setup is not perfectly consistent, but I
reran the tests several times to confirm that the bigint column
always performed slightly slower than the varchar column. My
guess is this happens because the like filter requires the type to be a string
type, so SQL Server will need to convert on the fly. However, this is very
quick, so the end result is more or less the same as varchar.
My first idea when I heard about this problem was that we should try and add an index on the MSISDN column regardless if the like query can use it optimally or not. If nothing else it should be easier for SQL Server to look through an index instead of the full table. But, I was on vacation at the time and did not have the chance to try. Instead, let's do it now and see if there's any improvement.
create nonclustered index IX_U_Msisdn on U (Msisdn);
create nonclustered index IX_U_MsisdnVarchar on U (MsisdnVarchar);
create nonclustered index IX_U_MsisdnInt on U (MsisdnInt);
And this is the result after rerunning the queries after index creation:
| Test | Total time | Avg CPU (s) | Avg Actual (s) | Logical Reads |
|---|---|---|---|---|
| Baseline | 01:05.47 | 3.7452 | 0.3224 | 61644 |
| Varchar Column | 00:18.75 | 0.9894 | 0.0884 | 61644 |
| Bigint Column | 00:18.94 | 1.0060 | 0.0895 | 61644 |
| Baseline Indexed | 05:58.25 | 1.7805 | 1.7865 | 11828 |
| Varchar Indexed | 02:17.17 | 0.6545 | 0.6810 | 9041 |
| Bigint Indexed | 00:21.27 | 1.1159 | 0.1009 | 61644 |
Result ???
Very interesting result! No query got faster in total time! However, most of
them uses significantly less CPU. Let's take a look at the query plan of the
Varchar Indexed
query:
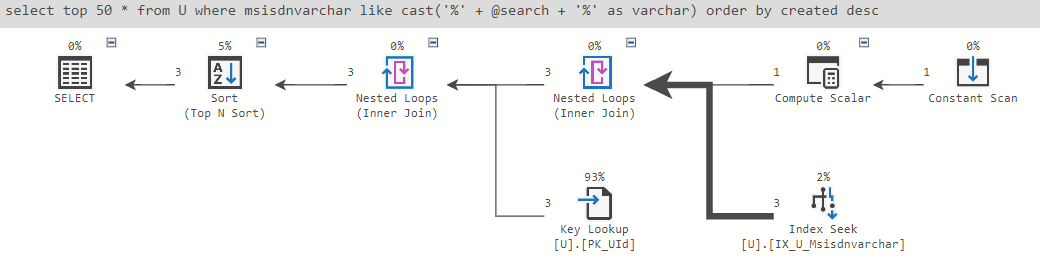
And compare it to the Bigint Column
query:

Ah, as we can see the Bigint Column
query has a
Parallelism
step, while the Varchar indexed
query does not. This
should explain why Bigint Column
uses more CPU than actual time. We
also see that Varchar indexed
spends most on Key lookup
on the
table itself. If the table had significantly more rows, I would expect the
indexed queries to come out ahead also in actual time and not just CPU time,
but for now lets move on.
With the easy low-hanging fruits out of the way, we can now turn to more
complex solutions. Let's first take a look at trigrams
.
There's a great post by Paul White here: Trigram Wildcard String Search in SQL Server that goes into details of how to do wildcard search with trigrams. Trigrams are a variant of n-gram that splits up both the search term and the text to search into 3 character substrings. These can then be indexed and as a result give a great speedup. I won't go into detail since Paul already covered it, but below is the various SQL I used:
CREATE FUNCTION dbo.GenerateTrigrams...
CREATE FUNCTION dbo.GenerateTrigrams (@string varchar(255))
RETURNS table
WITH SCHEMABINDING
AS RETURN
WITH
N16 AS
(
SELECT V.v
FROM
(
VALUES
(0),(0),(0),(0),(0),(0),(0),(0),
(0),(0),(0),(0),(0),(0),(0),(0)
) AS V (v)),
-- Numbers table (256)
Nums AS
(
SELECT n = ROW_NUMBER() OVER (ORDER BY A.v)
FROM N16 AS A
CROSS JOIN N16 AS B
),
Trigrams AS
(
-- Every 3-character substring
SELECT TOP (CASE WHEN LEN(@string) > 2 THEN LEN(@string) - 2 ELSE 0 END)
trigram = SUBSTRING(@string, N.n, 3)
FROM Nums AS N
ORDER BY N.n
)
-- Remove duplicates and ensure all three characters are alphanumeric
SELECT DISTINCT
T.trigram
FROM Trigrams AS T
WHERE
-- Binary collation comparison so ranges work as expected
T.trigram COLLATE Latin1_General_BIN2 NOT LIKE '%[^A-Z0-9a-z]%';
CREATE TABLE dbo.Trigram...
-- Table to store the trigrams
CREATE TABLE dbo.Trigram
(
UserId UNIQUEIDENTIFIER NOT NULL,
Trigram char(3) NOT NULL
);
-- Generate trigrams
INSERT INTO dbo.Trigram WITH (TABLOCKX)
(UserId, Trigram)
SELECT
U.UserId,
GT.trigram
FROM U
CROSS APPLY GenerateTrigrams(U.msisdnVarchar) AS GT;
-- clustered "covering" index in trigram, userid
CREATE UNIQUE CLUSTERED INDEX CUQ_Trigram_Trigram_UserId ON dbo.Trigram (Trigram, UserId) WITH (ONLINE = ON);
CREATE VIEW dbo.TrigramCounts...
-- view of unique trigrams counted
CREATE VIEW dbo.TrigramCounts
WITH SCHEMABINDING
AS
SELECT ET.Trigram, cnt = COUNT_BIG(*)
FROM dbo.Trigram AS ET
GROUP BY ET.Trigram;
-- Materialize the view
CREATE UNIQUE CLUSTERED INDEX CUQ_TrigramCounts_Trigram ON TrigramCounts (Trigram);
CREATE FUNCTION dbo.GetBestTrigrams...
-- Most selective trigrams for a search string
-- Always returns a row (NULLs if no trigrams found)
CREATE FUNCTION dbo.GetBestTrigrams (@string varchar(255))
RETURNS table
WITH SCHEMABINDING AS
RETURN
SELECT
-- Pivot
trigram1 = MAX(CASE WHEN BT.rn = 1 THEN BT.trigram END),
trigram2 = MAX(CASE WHEN BT.rn = 2 THEN BT.trigram END),
trigram3 = MAX(CASE WHEN BT.rn = 3 THEN BT.trigram END)
FROM
(
-- Generate trigrams for the search string
-- and choose the most selective three
SELECT TOP (3)
rn = ROW_NUMBER() OVER (
ORDER BY ETC.cnt ASC),
GT.trigram
FROM dbo.GenerateTrigrams(@string) AS GT
JOIN dbo.TrigramCounts AS ETC
WITH (NOEXPAND)
ON ETC.trigram = GT.trigram
ORDER BY
ETC.cnt ASC
) AS BT;
CREATE FUNCTION dbo.GetTrigramMatchIDs...
-- Returns UserIds matching all provided (non-null) trigrams
CREATE FUNCTION dbo.GetTrigramMatchIDs
(
@Trigram1 char(3),
@Trigram2 char(3),
@Trigram3 char(3)
)
RETURNS @IDs table (UserId UNIQUEIDENTIFIER PRIMARY KEY)
WITH SCHEMABINDING AS
BEGIN
IF @Trigram1 IS NOT NULL
BEGIN
IF @Trigram2 IS NOT NULL
BEGIN
IF @Trigram3 IS NOT NULL
BEGIN
-- 3 trigrams available
INSERT @IDs (UserId)
SELECT ET1.UserId
FROM dbo.Trigram AS ET1
WHERE ET1.trigram = @Trigram1
INTERSECT
SELECT ET2.UserId
FROM dbo.Trigram AS ET2
WHERE ET2.trigram = @Trigram2
INTERSECT
SELECT ET3.UserId
FROM dbo.Trigram AS ET3
WHERE ET3.trigram = @Trigram3
OPTION (MERGE JOIN);
END;
ELSE
BEGIN
-- 2 trigrams available
INSERT @IDs (UserId)
SELECT ET1.UserId
FROM dbo.Trigram AS ET1
WHERE ET1.trigram = @Trigram1
INTERSECT
SELECT ET2.UserId
FROM dbo.Trigram AS ET2
WHERE ET2.trigram = @Trigram2
OPTION (MERGE JOIN);
END;
END;
ELSE
BEGIN
-- 1 trigram available
INSERT @IDs (UserId)
SELECT ET1.UserId
FROM dbo.Trigram AS ET1
WHERE ET1.trigram = @Trigram1;
END;
END;
RETURN;
END;
CREATE FUNCTION dbo.TrigramSearch...
CREATE OR ALTER FUNCTION dbo.TrigramSearch
(
@Search varchar(255)
)
RETURNS table
WITH SCHEMABINDING
AS
RETURN
SELECT
Result.UserId
FROM dbo.GetBestTrigrams(@Search) AS GBT
CROSS APPLY
(
-- Trigram search
SELECT
U.UserId,
U.msisdn
FROM dbo.GetTrigramMatchIDs
(GBT.trigram1, GBT.trigram2, GBT.trigram3) AS MID
JOIN dbo.U
ON U.UserId = MID.UserId
WHERE
-- At least one trigram found
GBT.trigram1 IS NOT NULL
AND U.msisdnVarchar LIKE @Search
UNION ALL
-- Non-trigram search
SELECT
U.UserId,
U.msisdn
FROM dbo.U
WHERE
-- No trigram found
GBT.trigram1 IS NULL
AND U.msisdnVarchar LIKE @Search
) AS Result;
Phew, that was quite a bit of logic! Lets take a look at the query we need to use. We need to join in the U table to get the full row out. Sometimes this query does not use a loop to resovle the join, so I add a loop hint as well. As long as not too many rows are found its better to first get matching userIds, and then join in the full table:
select top 50 U.*
from TrigramSearch('%' + @search + '%') as TS
inner loop join U on U.UserId = TS.UserId
order by U.created desc;
With all the setup done, and a query to test it, lets look at the result. I
have run the test both without any additional index and with the index on the
varchar MSISDN column:
| Test | Total time | Avg CPU (s) | Avg Actual (s) | Logical Reads |
|---|---|---|---|---|
| Baseline | 01:05.47 | 3.7452 | 0.3224 | 61644 |
| Varchar Column | 00:18.75 | 0.9894 | 0.0884 | 61644 |
| Bigint Column | 00:18.94 | 1.0060 | 0.0895 | 61644 |
| Baseline Indexed | 05:58.25 | 1.7805 | 1.7865 | 11828 |
| Varchar Indexed | 02:17.17 | 0.6545 | 0.6810 | 9041 |
| Bigint Indexed | 00:21.27 | 1.1159 | 0.1009 | 61644 |
| Trigram | 00:04.50 | 0.0119 | 0.0176 | 1623 |
| Trigram indexed | 00:03.57 | 0.0103 | 0.0135 | 1096 |
Result unindexed: 18x faster
Result indexed: 24x faster
Nice! Here we have a real speedup! We now reach performance levels were we dont need to be worried the query will overload the database, or levels that could allow the query to be exposed to a more heavily used endpoint than admin search.
Is it possible to do something even faster? Using a bigint column
for the MSISDN didnt help. But maybe something similar applied to the Trigrams
could? What if instead of using 3 character trigrams we used integers for an
"intgram"? The n in "n-gram" could then become 16 bit integer.
I chose 16bit integer (smallint) as the n-gram size based on:
Given the above, lets use a 16bit integer instead of char(3) for
the trigrams intgrams. The code for this is more or less the same
as for the trigrams, except the data type is a smallint instead
of a char(3). Only the generate trigram intgram
function have significant changes, the rest is mainly casts. Note also that
there's some optimization left, it could likely be faster to get the intgram
mathematically than by substring which is how its implemented now.
CREATE FUNCTION dbo.GenerateSmallintgrams...
CREATE OR ALTER FUNCTION dbo.GenerateSmallintgrams (@m bigint)
RETURNS table
WITH SCHEMABINDING
AS RETURN
WITH n AS (
SELECT n from (VALUES
(1),(2),(3),(4),(5),(6),(7),(8),(9),
(10),(11),(12),(13),(14),(15),(16),(17)
) as v (n)
), g as (
SELECT TOP (CASE WHEN @m > 999 THEN cast(log10(@m)+1 as int) - 3 ELSE 0 END)
cast(SUBSTRING(cast(@m as varchar), n.n, 4) as smallint) as intgram
FROM n
ORDER BY n.n
)
SELECT
DISTINCT g.intgram
FROM g
CREATE TABLE dbo.SmallIntgram...
-- Table to store the trigrams
CREATE TABLE SmallIntgram
(
UserId uniqueidentifier NOT NULL,
Intgram smallint NOT NULL
);
-- Generate trigrams
INSERT SmallIntgram WITH (TABLOCKX)
(UserId, Intgram)
SELECT
u.UserId,
GT.Intgram
FROM u
CROSS APPLY dbo.GenerateSmallintgrams(u.msisdnint) AS GT;
-- clustered "covering" index in intgram, userid
CREATE UNIQUE CLUSTERED INDEX [CUQ_SmallIntgram_Intgram_UserId]
ON dbo.SmallIntgram (Intgram, UserId)
CREATE VIEW dbo.SmallIntgramCounts...
-- view of unique smallintgrams counted
CREATE VIEW dbo.SmallIntgramCounts
WITH SCHEMABINDING
AS
SELECT SI.Intgram, cnt = COUNT_BIG(*)
FROM dbo.SmallIntgram AS SI
GROUP BY SI.Intgram;
GO
-- Materialize the view
CREATE UNIQUE CLUSTERED INDEX CUQ_SmallIntgramCounts_Intgram
ON SmallIntgramCounts (Intgram);
CREATE FUNCTION dbo.GetBestSmallIntgrams...
CREATE OR ALTER FUNCTION dbo.GetBestSmallIntgrams (@msisdn bigint)
RETURNS table
WITH SCHEMABINDING AS
RETURN
SELECT
-- Pivot
intgram1 = MAX(CASE WHEN BT.rn = 1 THEN BT.intgram END),
intgram2 = MAX(CASE WHEN BT.rn = 2 THEN BT.intgram END),
intgram3 = MAX(CASE WHEN BT.rn = 3 THEN BT.intgram END)
FROM
(
-- Generate intgrams for the search string
-- and choose the most selective three
SELECT TOP (3)
rn = ROW_NUMBER() OVER (ORDER BY ETC.cnt ASC),
GT.intgram
FROM dbo.GenerateSmallIntgrams(@msisdn) AS GT
JOIN dbo.SmallIntgramCounts AS ETC
WITH (NOEXPAND)
ON ETC.intgram = GT.intgram
ORDER BY
ETC.cnt ASC
) AS BT;
CREATE FUNCTION dbo.GetSmallIntgramMatchIDs...
CREATE OR ALTER FUNCTION dbo.GetSmallIntgramMatchIDs
(
@intgram1 smallint,
@intgram2 smallint,
@intgram3 smallint
)
RETURNS @IDs table (UserId UNIQUEIDENTIFIER PRIMARY KEY)
WITH SCHEMABINDING AS
BEGIN
IF @intgram1 IS NOT NULL
BEGIN
IF @intgram2 IS NOT NULL
BEGIN
IF @intgram3 IS NOT NULL
BEGIN
-- 3 intgrams available
INSERT @IDs (UserId)
SELECT ET1.UserId
FROM dbo.Smallintgram AS ET1
WHERE ET1.intgram = @intgram1
INTERSECT
SELECT ET2.UserId
FROM dbo.Smallintgram AS ET2
WHERE ET2.intgram = @intgram2
INTERSECT
SELECT ET3.UserId
FROM dbo.Smallintgram AS ET3
WHERE ET3.intgram = @intgram3
OPTION (MERGE JOIN);
END;
ELSE
BEGIN
-- 2 intgrams available
INSERT @IDs (UserId)
SELECT ET1.UserId
FROM dbo.Smallintgram AS ET1
WHERE ET1.intgram = @intgram1
INTERSECT
SELECT ET2.UserId
FROM dbo.Smallintgram AS ET2
WHERE ET2.intgram = @intgram2
OPTION (MERGE JOIN);
END;
END;
ELSE
BEGIN
-- 1 intgram available
INSERT @IDs (UserId)
SELECT ET1.UserId
FROM dbo.Smallintgram AS ET1
WHERE ET1.intgram = @intgram1;
END;
END;
RETURN;
END;
CREATE FUNCTION dbo.SmallIntgramSearch...
CREATE OR ALTER FUNCTION dbo.SmallIntgramSearch
(
@search bigint
)
RETURNS table
WITH SCHEMABINDING
AS
RETURN
SELECT
Result.UserId
FROM dbo.GetBestSmallIntgrams(@Search) AS GBT
CROSS APPLY
(
-- Intgram search
SELECT
U.UserId,
U.msisdn
FROM dbo.GetSmallIntgramMatchIDs
(GBT.intgram1, GBT.intgram2, GBT.intgram3) AS MID
JOIN dbo.U
ON U.UserId = MID.UserId
WHERE
-- At least one intgram found
GBT.intgram1 IS NOT NULL
AND U.msisdnvarchar LIKE '%' + cast(@Search as varchar) + '%'
UNION ALL
-- Non-intgram search
SELECT
U.UserId,
U.msisdn
FROM dbo.U
WHERE
-- No trigram found
GBT.intgram1 IS NULL
AND U.msisdnvarchar LIKE '%' + cast(@Search as varchar) + '%'
) AS Result;
And just like with the trigrams, the original table needs to be joined in with
a Loop join hint to ensure speedy execution when we run the full
query for benchmark:
select top 50 U.*
from SmallIntgramSearch(@search) as TS
inner loop JOIN U on U.UserId = TS.UserId
order by created desc;
This is the final test, and the full results are listed in the table below, with the winners in bold:
| Test | Total time | Avg CPU (s) | Avg Actual (s) | Logical Reads |
|---|---|---|---|---|
| Baseline | 01:05.47 | 3.7452 | 0.3224 | 61644 |
| Varchar Column | 00:18.75 | 0.9894 | 0.0884 | 61644 |
| Bigint Column | 00:18.94 | 1.0060 | 0.0895 | 61644 |
| Baseline Indexed | 05:58.25 | 1.7805 | 1.7865 | 11828 |
| Varchar Indexed | 02:17.17 | 0.6545 | 0.6810 | 9041 |
| Bigint Indexed | 00:21.27 | 1.1159 | 0.1009 | 61644 |
| Trigram | 00:04.50 | 0.0119 | 0.0176 | 1623 |
| Trigram indexed | 00:03.57 | 0.0103 | 0.0135 | 1096 |
| Intgram | 00:03.40 | 0.0096 | 0.0123 | 2919 |
| Intgram indexed | 00:03.40 | 0.0072 | 0.0119 | 1598 |
Result unindexed: 26x faster
Result indexed: 27x faster
A nice speedup compared to baseline! If the 1.1x faster time is worth it
compared to the more generic trigram is of course a tricky question. In most
cases I would sadly think not. At the same time I suspect the
Intgram
method will scale better with higher rowcount, but I have not
confirmed this. Another important consideration is the resource usage, looking
at CPU intgram is 1.4x more efficient copmared with trigram.
Given the small difference between Trigram
and IntGram
, and the
modest improvement by adding indexes it can be good to also look at the sizes
of the additional tables and indexes. Disk is almost always cheap, but
table/index size will also affect how much can fit in RAM. This can be hard to
show in a benchmark, as normally there's no other queries on the same or other
tables running concurrently competing for the almost always limited RAM
memory.
| Table/index | Page count | Size (MB) |
|---|---|---|
| SmallIntgram | 48613 | 380 |
| Trigram | 56386 | 440 |
| IX_U_Msisdn | 10809 | 84 |
| IX_U_MsisdnInt | 6729 | 53 |
| IX_U_Msisdnvarchar | 8316 | 65 |
| PK_UId | 60830 | 475 |
| Column | Msisdn (nvarchar) |
MsisdnVarchar (varchar) |
MsisdnInt (bigint) |
|---|---|---|---|
| Size | 61MB | 42MB | 29MB |
Here we can see that the Trigram table is using more space than the Intgram
table. This is expected, and I actually thought the difference would be larger
given that a smallint should be significantly smaller than an
char(3). But it turns out there's too much overhad and the saving
is mostly because the Trigram table has 16m rows, while the Intgram table
"only" has 14m rows. The space saving because of data type is only a couple of
percent. We can also see that there's a significant difference in how much
storage the nvarchar, varchar and
bigint indexes uses. As expected the index storage matches well
with approximate column sizes as shown in the table above.
And that was that. In the end, at work we decided to be happy with the
varchar conversion, and revisit this problem in the future. Maybe
product requirements have changed by then, i.e. by requiring a more
comprehensive search or changing usage patterns. As is often the case, at work
there's more to consider than the pure technical challenge. But I still think
its pretty neat with a 27x improvement just
from some T-SQL and
an index on a query that is supposedly not possible to index!